Chapter 13: Samples and surveys
STAT 1010 - Fall 2022
Learning outcomes
- Know basic sampling vocabulary.
- Understand why randomization is important and describe different sampling methods
- How to sample in
R - Know pitfalls related to sampling
Revision
Intro
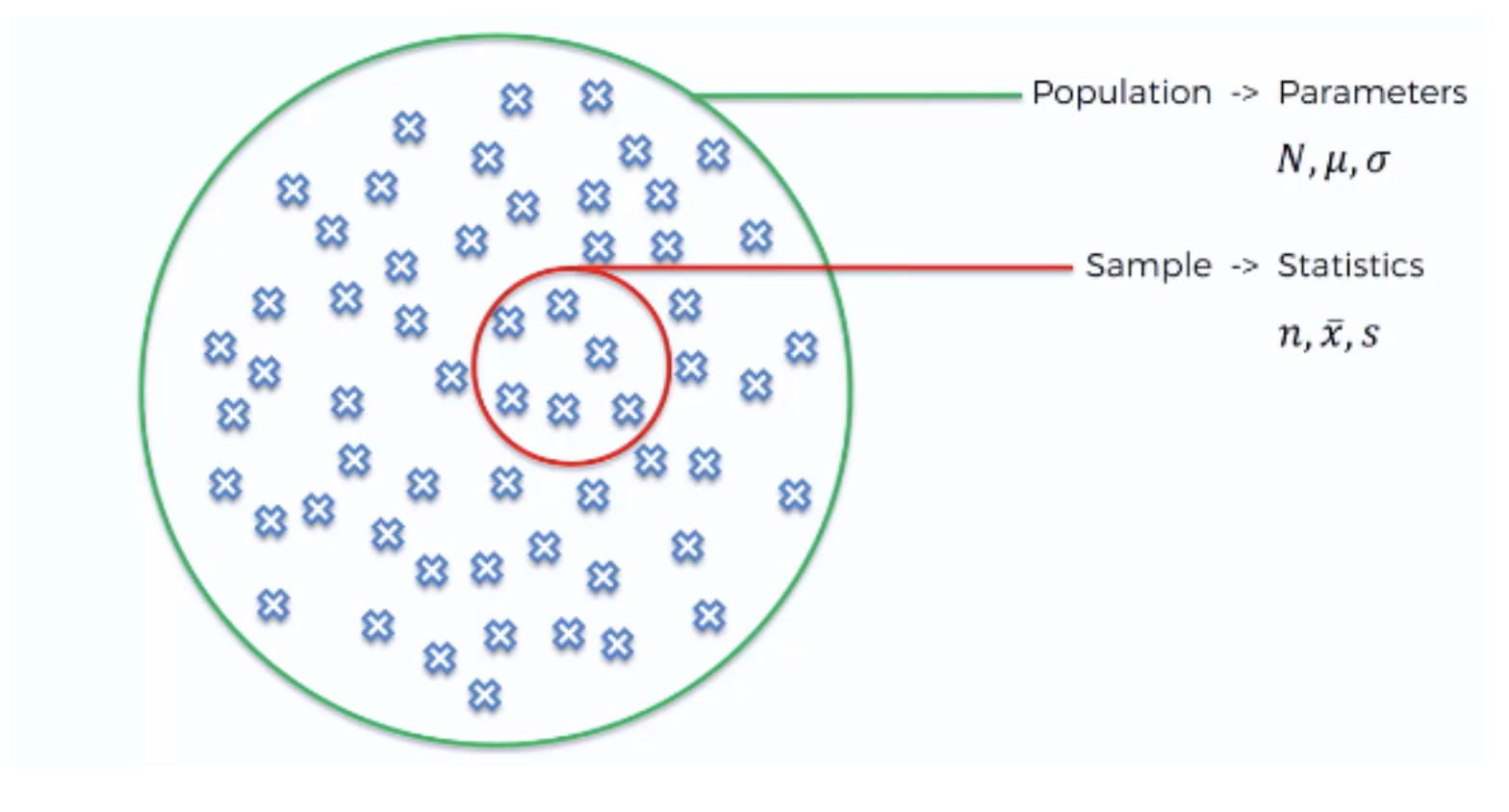
- survey : researchers ask questions of a subset of people who belong to a population.
- this subset of the population that reserachers ask is called the sample
- a sample is representative if it seeks to accurately reflect the characteristics of the larger group
- bias occurs in sampling when samples systematically omit a portion of the population
- random samples, where each unit has an equal probability of being choosen, are important
Predictive policing
- Research question - Can police use crime data from disparate sources to anticipate and prevent future crime?
- population - all crime
- sample - arrests recorded in police database
- Is this a random sample?
- arrests is a surrogate measurement because crime is hard to track
Predictive policing
- for arrests to occur police must be present
- some areas are over policed, so have more arrests
- this algorithm sends police to those areas
- read more here
- use census data to predict crime instead of arrests, we may do better
Census
- sample everyone in the population
- this is often difficult because some individuals are hard to locate, and these people may have certain characterisitics that distinguish them from the rest of the population
- Populations move so getting a perfect measure is hard.
- A census may be more complex than sampling
Landon vs Roosevelt
- Literary digest - correctly predicted presidential elections from 1916 - 1932 with mock ballots
- 1936 election
- 10 million ballots
- Landon win by landslide with 57%
- 10 million names and addresses in 1936
- poor people were unlikely to have phones, so they over sampled the wealthy
- Gallup predicted a Roosevelt win
- weighting can be used to correct biased samples
Sampling

Sampling
- tasting is analogous to exploratory analysis
- stirring helps ensure that the taste is representative because it randomizes
- if we add ingredients and don’t stir we may get a biased sample
- if we generalize and decide that it needs more salt, that’s an inference
Sampling frame
- lists every member of the population of interest
- can be complex to identify
- sample from registered voters, but really want people who will vote
- hypothetical populations are more complex
- a brewery must sample hops across farmers, and different geographic regions prior to formalizing brewing
Simple random sample
Stratified sampling
Cluster sample
Sampling
Randomly select cases from the population, where there is no implied connection between the points that are selected.
Strata are made up of similar observations. We take a simple random sample from each stratum.
Clusters are usually not made up of homogeneous observations. We take a simple random sample of clusters, and then sample all observations in that cluster. Usually preferred for economical reasons.
Sampling in R
Not great sampling methods
- voluntary response
- convenience sampling - asking friends or families feedback about your product
Warnings
- sampling frame match population
- sampling method
- rate of nonresponse - how many people did not answer
- wording of the question - do you like this class
- interviewer affects - you are more likely to tell Patrick that you do not like this course than me
- survivor bias - we don’t know how students who did not stay in this class feel about it