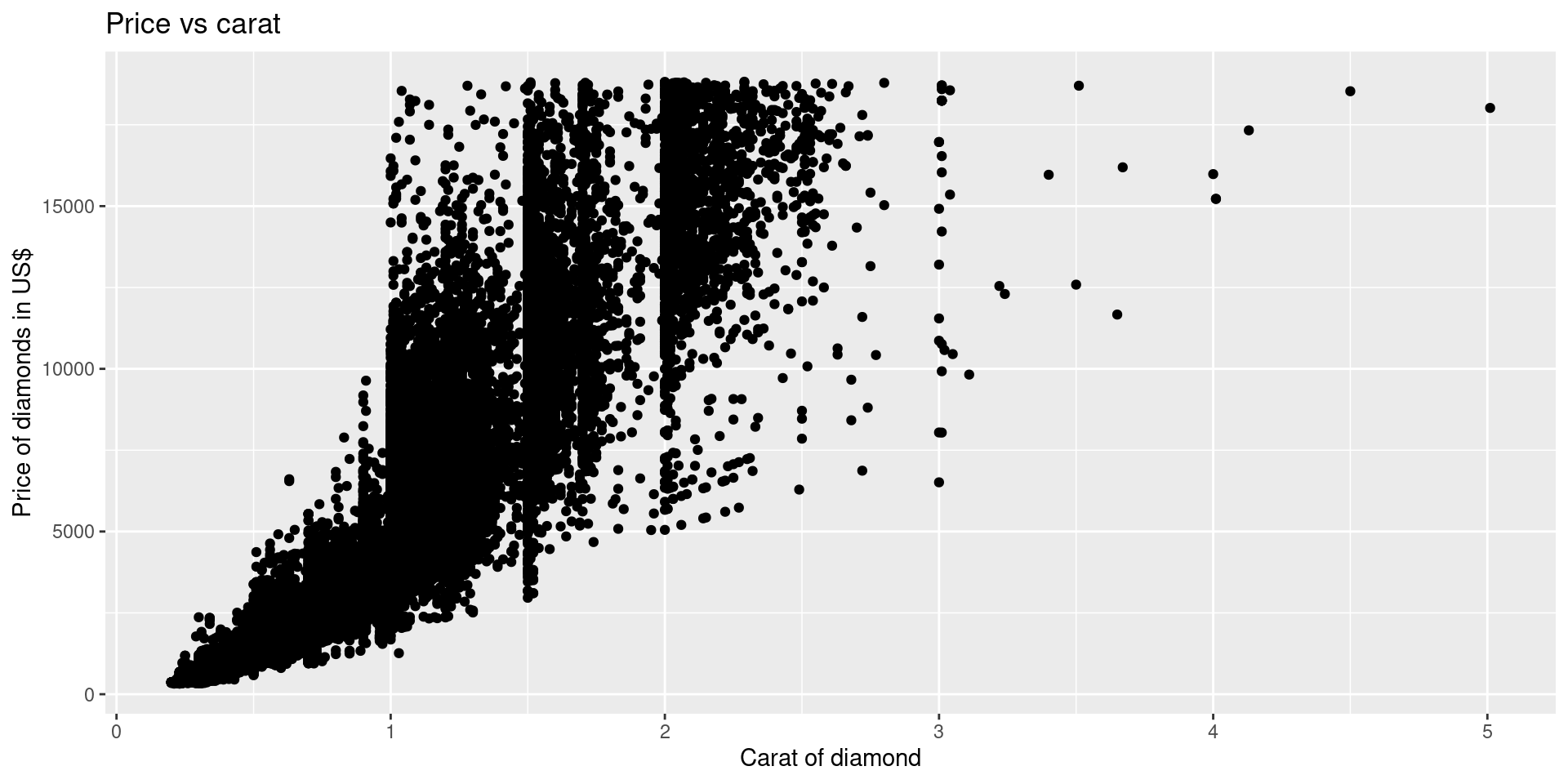
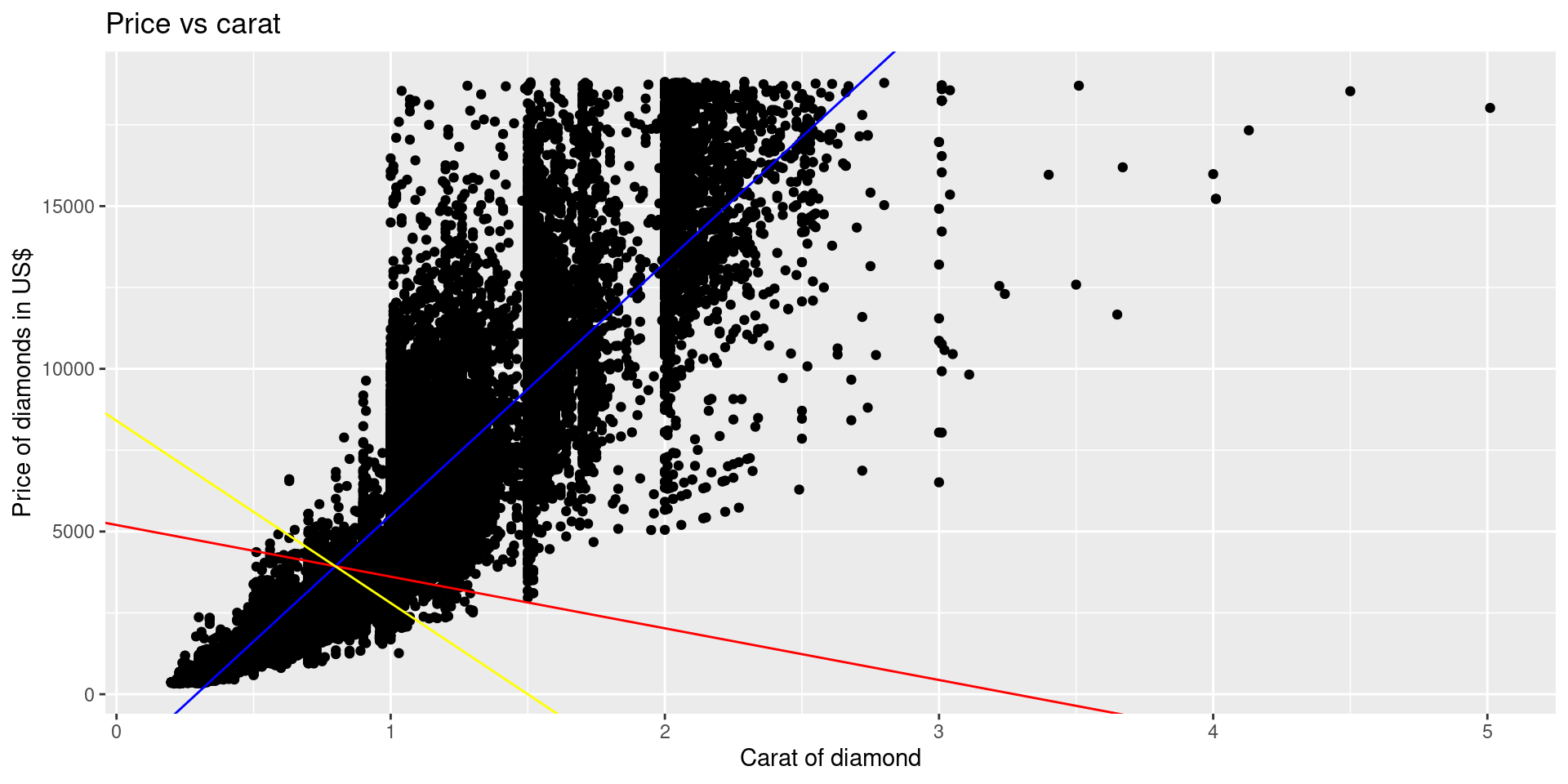
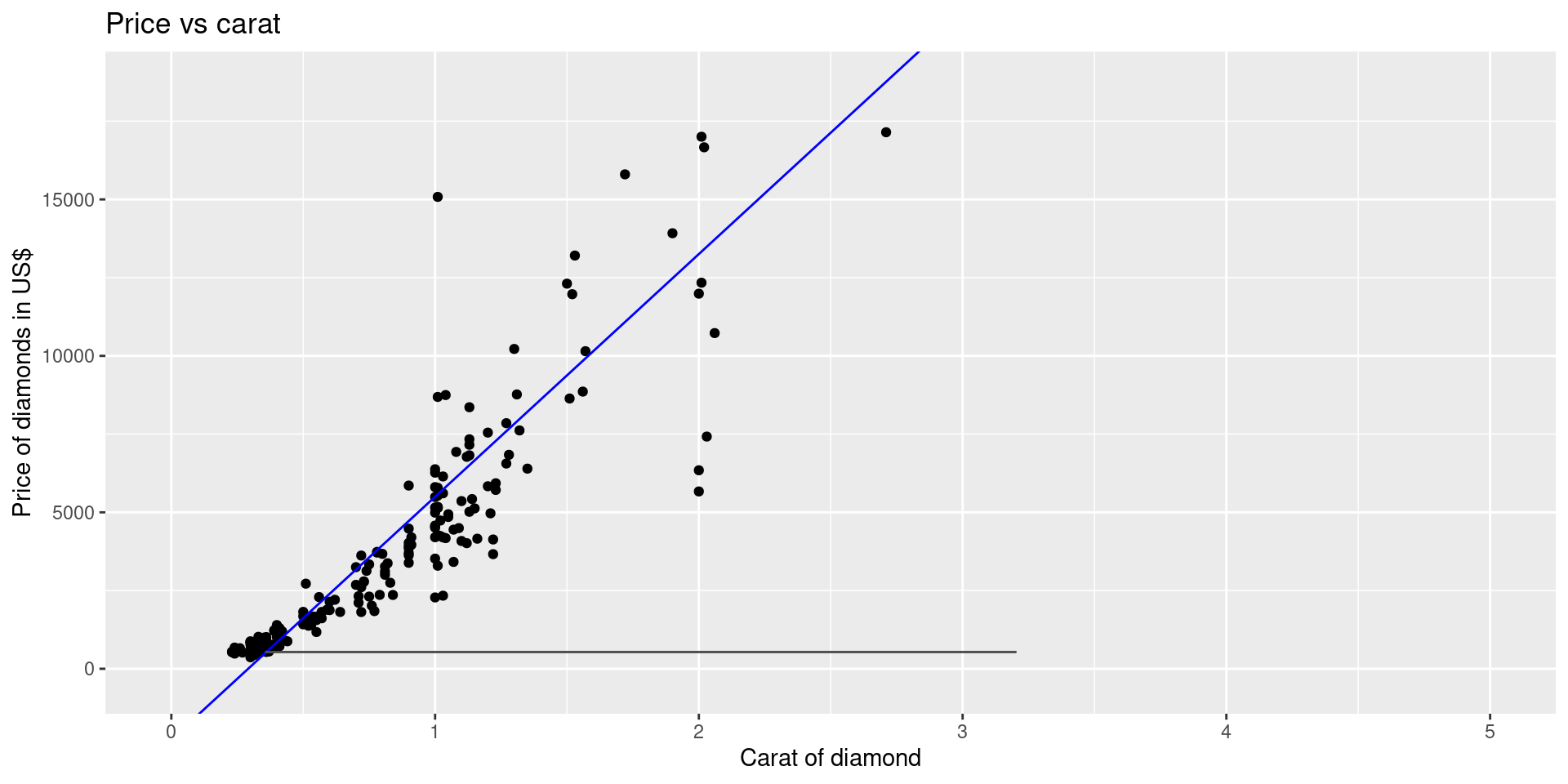
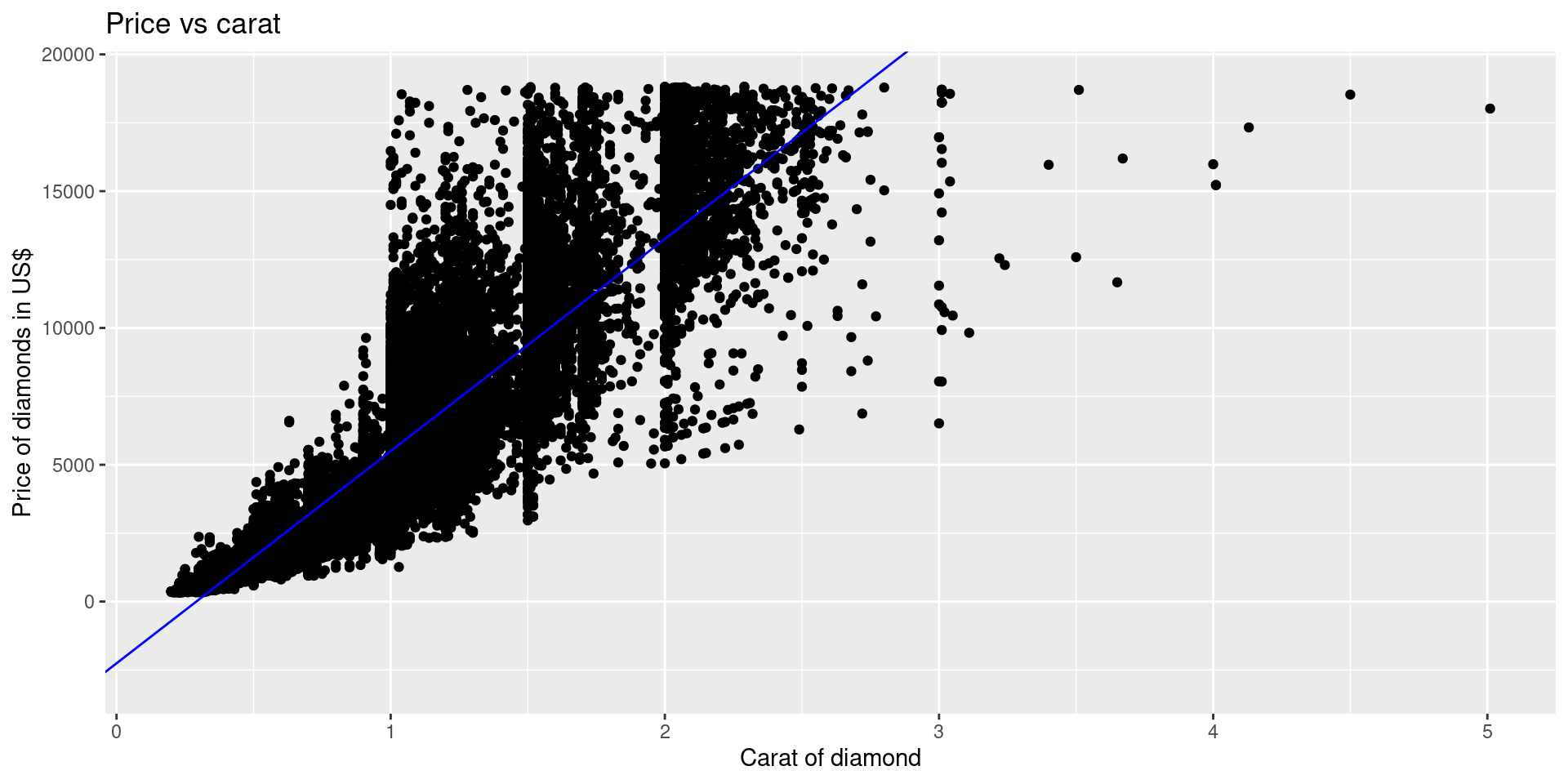
Interpretations
\[\widehat{\text{price}} = -2256.36 + 7756.426 \cdot \text{carat}\]
Intercept: For a diamonds that weighs 0 carats, we expect the price to be US$\(-2256.36\).
Slope: For every 0.1 carat increase in diamond weight, we expect the price in $US to increase by 776, on average.
Example 3
A manufacturing plant receives orders for customized mechanical parts. The orders vary in size, from about 30 to 130 units. After configuring the production line, a supervisor oversees the production. The least squares regression line that predicts time in hours using number of units to produce is:
\[\widehat{\text{time}} = 2.1 + 0.031 \cdot \text{Number of units}\] a. Interpret the intercept of the estimated line.
b. Interpret the slope of the estimated line.
c. Using the fitted line, estimate the amount of time needed for an order with 100 unit. Is this estimate an extrapolation?
d. Based on the fitted line, how much more time does an order with 100 units require over an order with 50 units?